
TL;DR
- Problem. Enterprise product attributes lived in a tangle of spreadsheets, side docs, and tribal knowledge. The CMS could not keep up with category-specific rules, and merchandisers were blocked on operations they should have owned themselves.
- My role. Senior product designer. I led systems design, attribute modeling, and interaction design with engineering and the merchandising organization.
- What changed. I designed a structured attribute system that captured the real rules governing how products are described, validated, and grouped, then turned that model into a CMS experience merchandisers could use without an engineer in the room.
- Result. Undocumented knowledge became a first-class, maintainable data model. Category teams could define, version, and roll out attribute rules directly, removing the engineering bottleneck.
- Why it mattered. Product data is the substrate for search, merchandising, compliance, and personalization. Fixing the attribute layer unlocked every downstream system that depended on it.
Large retail organizations run on product data.
Every item in the catalog may include hundreds of attributes: fabric, fit, sleeve length, pattern, compliance labels, country of origin, seasonal variants, and countless category-specific details.
In theory these attributes live in a CMS.
In reality, the system I inherited was something else entirely.
Years of business logic had accumulated across massive spreadsheets. Thousands of attributes were interconnected through implicit rules, exceptions, and dependencies. The system worked — but only because one person had spent years learning its internal logic.
Her knowledge was the infrastructure.
If she understood the system, it worked.
If she didn’t, things broke.
The company had reached the point where this was no longer sustainable.
My task was to turn this ecosystem of spreadsheets and tribal knowledge into a structured system that could scale.
The Real Problem Wasn't the Interface
At first glance, the project looked like a standard CMS redesign.
But the deeper I went, the clearer it became that the interface was not the real problem.
The real problem was the data model itself.
The existing system treated attributes as disconnected form fields.
But product data behaves more like a structured knowledge system:
• attributes depend on other attributes
• categories define allowable attribute sets
• vendor submissions require validation
• internal teams curate and refine product data over time
The system needed to reflect those relationships.
Without that structure, any CMS would eventually collapse back into spreadsheets.
Using AI to Map the Hidden System
Understanding the problem required reconstructing years of undocumented business logic.
I conducted hours of interviews with the team member who had been maintaining the system and recorded detailed transcripts of each session.
Instead of manually synthesizing everything, I used AI to accelerate the analysis.
I fed transcripts into the model and asked it to:
- identify workflows
- map entity relationships
- detect hidden dependencies
- surface contradictions
- highlight ambiguous rules
The AI didn’t design the system.
But it compressed a mountain of information into something I could actually reason about.
This transformed the discovery process from an impossible synthesis task into an iterative exploration.
Each cycle clarified more of the system.
Building a Prototype Instead of a Specification
Once the system’s logic became clearer, I decided not to stop at wireframes.
The domain complexity was simply too high for static designs.
Instead, I built a high-fidelity interactive prototype.
The prototype implemented:
• category hierarchies • attribute schemas • attribute dependency mapping • vendor submission flows • internal review workflows • validation rules • versioning logic
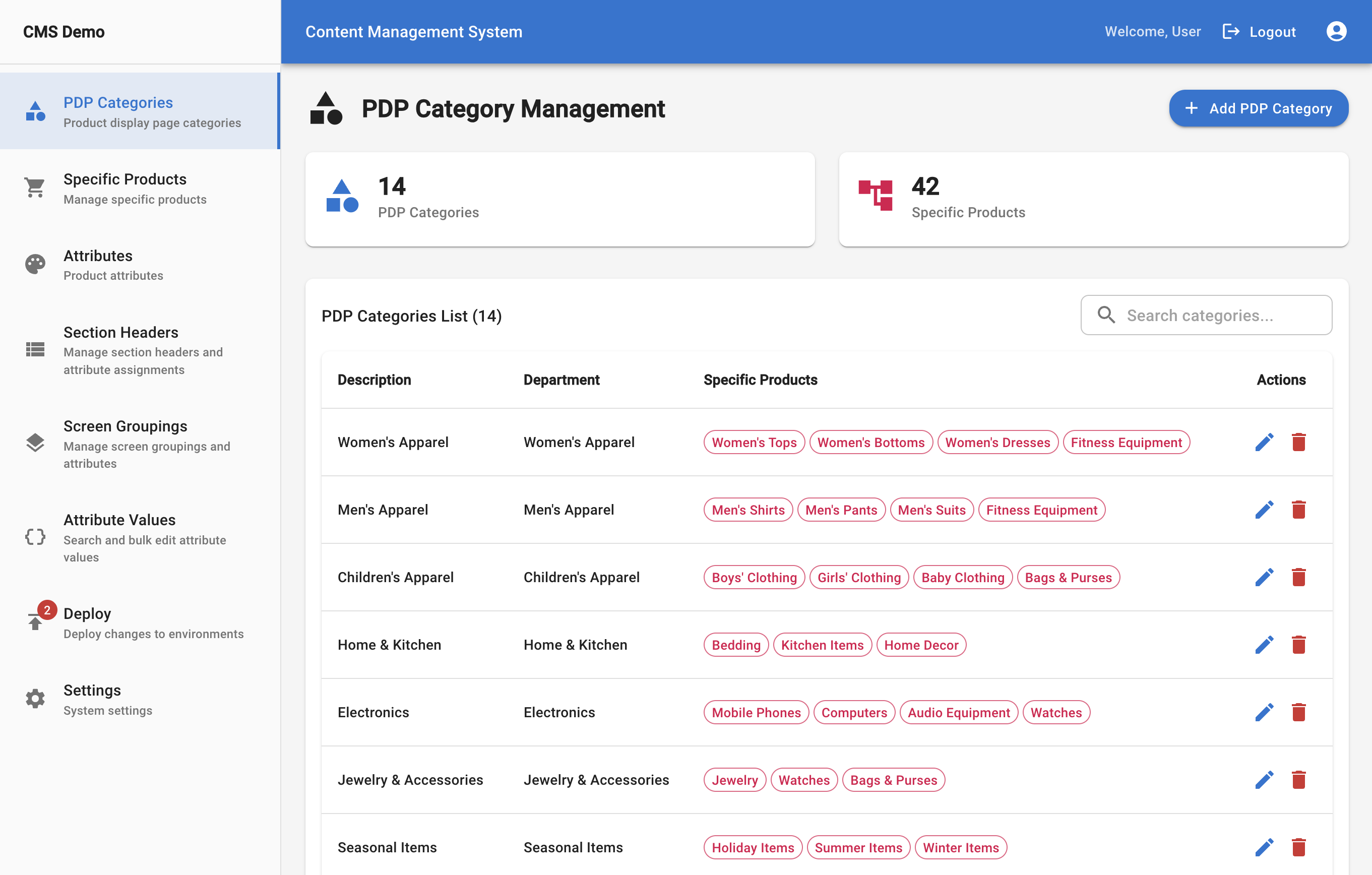
I used an AI coding agent to scaffold the interface, then refined the system myself.
AI accelerated the structure.
Human judgment shaped the product.
The goal was simple:
Create something stakeholders could actually use.
The Moment the System Became Real
The prototype immediately changed the conversation.
Instead of discussing abstract workflows, the team could interact with a working system.
As stakeholders explored the prototype, hidden edge cases surfaced quickly:
• vendor submissions conflicting with existing attributes
• seasonal overrides
• category exceptions
• validation conflicts
These insights had never surfaced during interviews.
They only appeared when people could see their process reflected back as software.
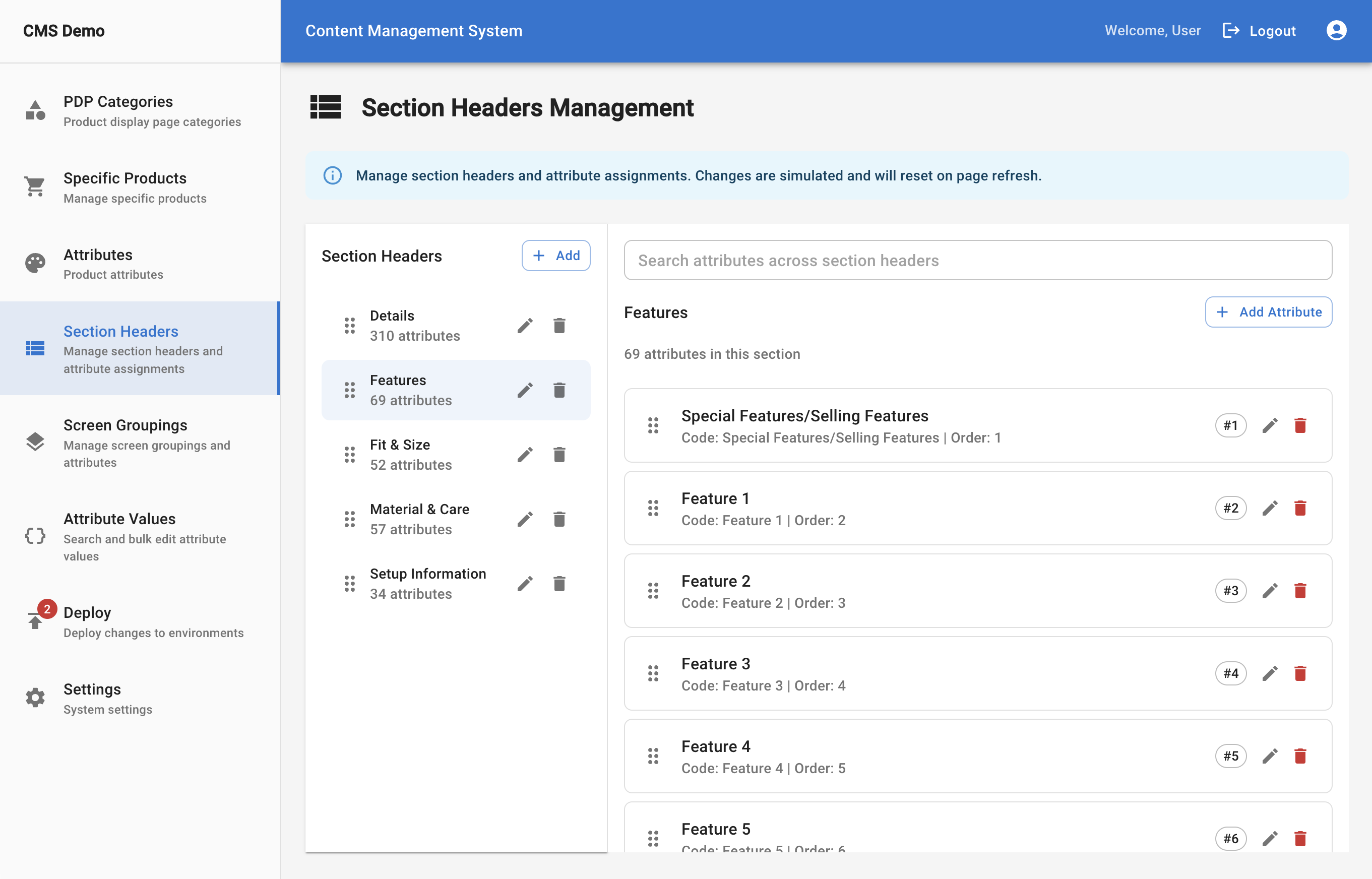
The prototype became the shared language the team had been missing.
It aligned product, engineering, and stakeholders around the same system.
It also transformed the knowledge that had lived in one person’s head into something the entire organization could understand.
What the Prototype Demonstrated
The system proposed a new architecture for managing product data.
Key principles included:
Attribute schemas defined by category
Categories define allowable attributes, reducing duplication and enforcing structure.
Centralized attribute definitions
Attributes become reusable entities rather than duplicated form fields.
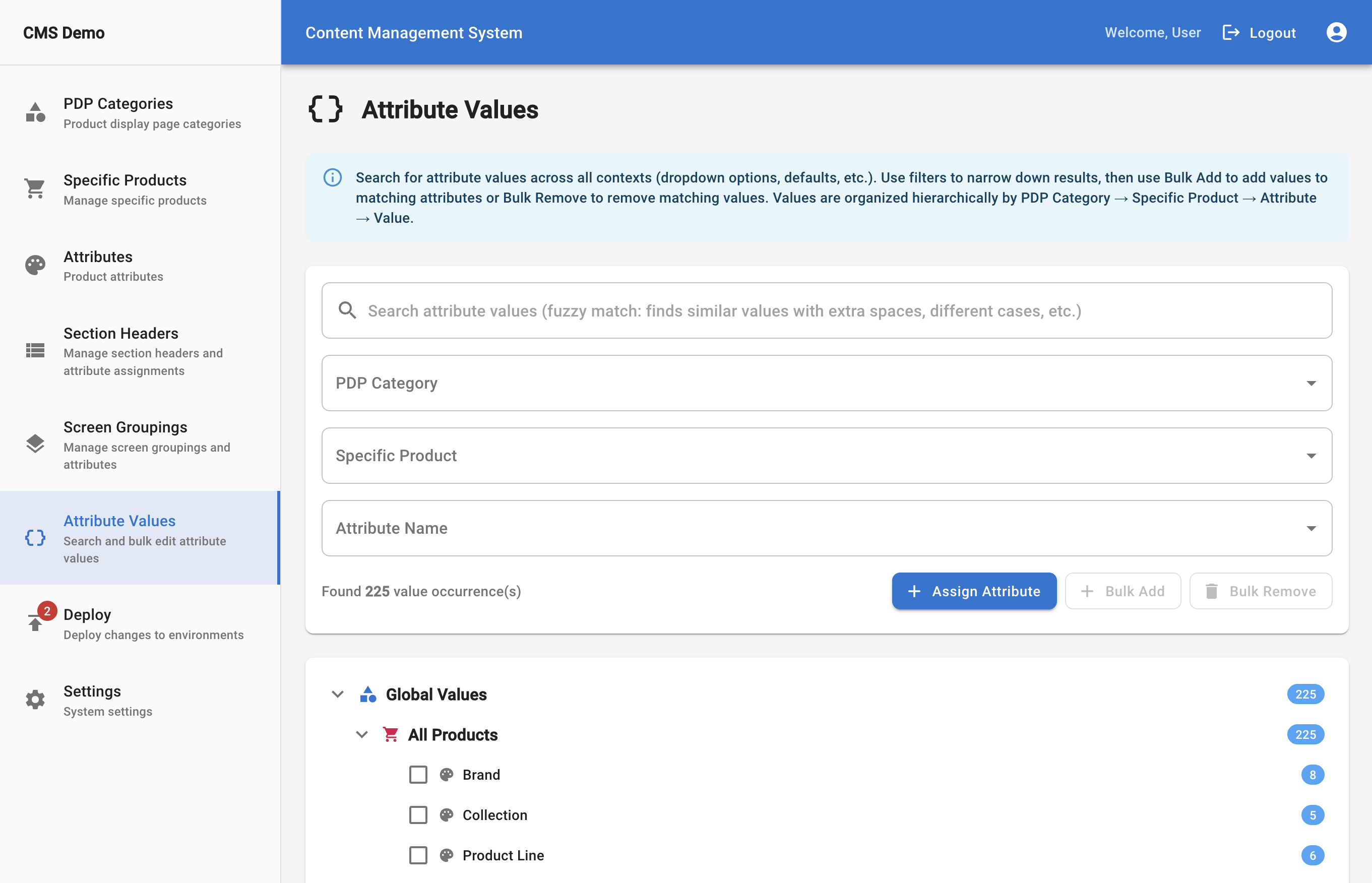
Vendor input validation
Vendor submissions pass through rule systems before entering the catalog.
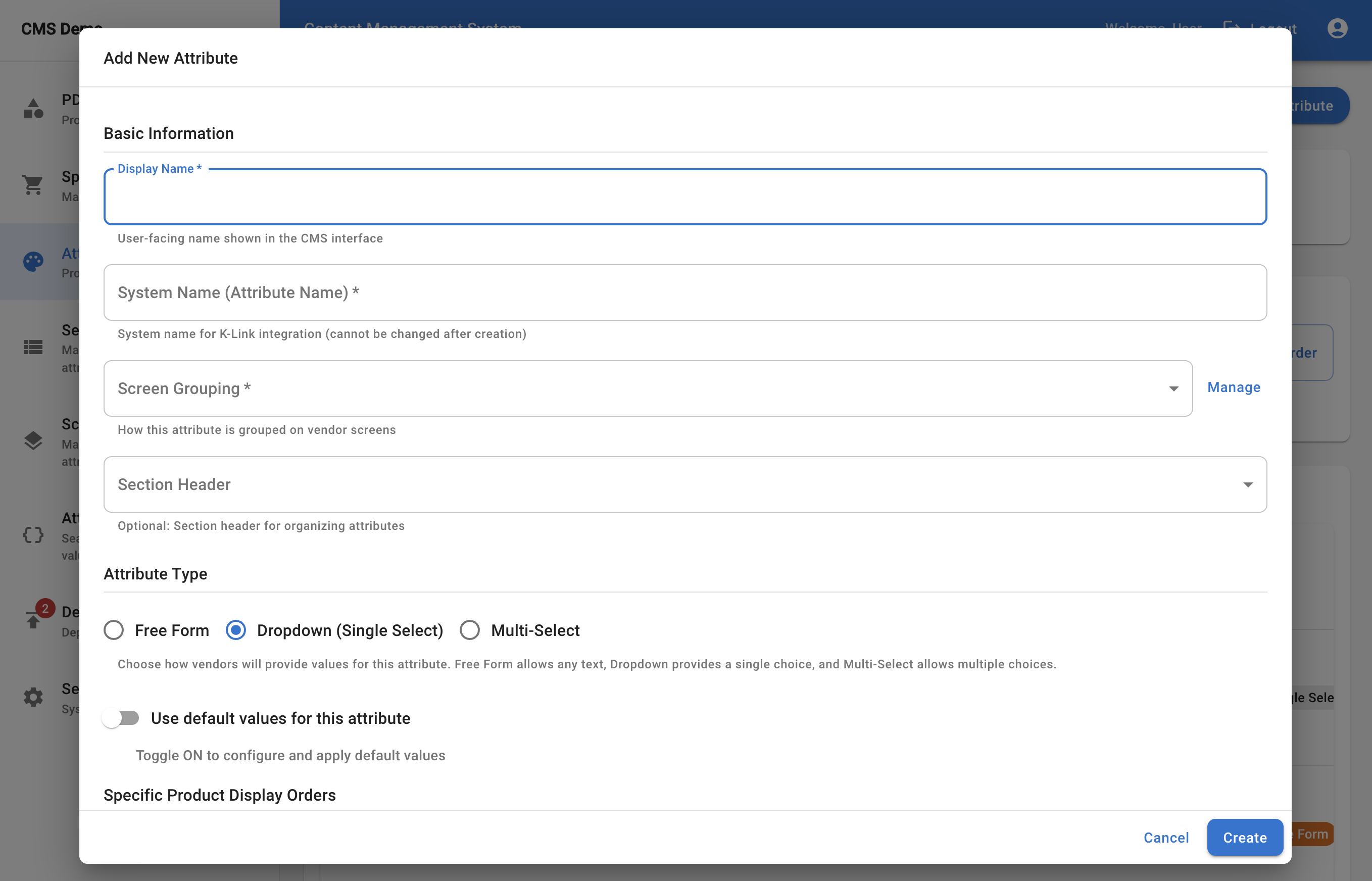
Editorial curation workflows
Internal teams refine and manage attributes rather than manually recreating them.
Together these changes transform a spreadsheet ecosystem into a scalable product data platform.
Lessons From the Project
Enterprise product systems are rarely limited by UI.
They are limited by poor conceptual models.
Once the underlying data structure improves, the user experience becomes dramatically simpler.
This project also reinforced the value of AI as a thinking partner.
AI didn’t design the system.
But it accelerated the synthesis of complex domain knowledge in a way that made the real design work possible.
Most importantly, the prototype made an invisible system visible.
And once people could see the system clearly, they could improve it together.
Why This Work Matters
Turning tribal knowledge into structured systems is one of the most important challenges inside large organizations.
When critical business logic exists only in people's heads or scattered across spreadsheets, the organization becomes fragile.
This prototype demonstrated a path toward a more resilient future:
A documented attribute model
A scalable category system
Clear vendor workflows
Structured validation logic
And most importantly, a system that no longer depends on any single person to function.